Blokada indeksacji powielonych adresów z parametrami

Blokada indeksacji powielonych adresów z parametrami czasami bywa trudna. Google nie zawsze respektuje wskazania w tagu canonical czy blokady w robots.txt.
Czasami nie ma też możliwości wstawienia odpowiedniego meta tagu robots w kodzie strony.
A blokować trzeba bo w witrynie indeksują się strony sortowań, filtrów lub czy adresów z „wewnątrz” skryptów.
W takim przypadku warto użyć jedno z narzędzi starego Google Search Console – „Parametry w adresach URL”.
W obecnej wersji jest ono dostępne w sekcji „Starsze narzędzia i raporty”
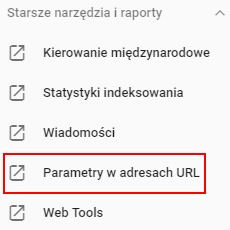
Po przejściu do niego otrzymujemy listę wykrytych przez Google parametrów z informacją o ich konfiguracji, działaniu i informacją o skanowaniu.
… Czytaj dalej »
 komentarze
komentarze